某养老院应用了“智能护管系统”,每位老人手上佩戴一个智能手环,可实时获取心率、血压和体温等数据,系统收集智能手环采集的数据并存储在数据库中,经分析后生成相关的报告,医生和老人可通过手机 APP 查看报告,管理员可通过 Web 客户端和手机 APP对系统进行维护。
lst = [5,9,2,6,4,7,3,0]
que = [0] * len(lst)
head = tail = 0
i = 0
while i < len(lst):
if lst[i] % 2 == 0:
que[tail] = lst.pop(i)
#lst.pop(i)删除列表 lst 中索引为 i 的元素,返回删除的元素
tail += 1
else:
i += 1
while head != tail:
lst.append(que[head])
head += 1
执行该程序段后,lst的值为( )
n=len(s)
for i in range(1, n):
![]()
for j in range(![]() )
)
if ![]()
s[j], s[j-1] = s[j-1], s[j]
flag = True
if flag==False:
break
上述程序段中方框可选代码为:①flag=True ②flag=False ③1,n-i+1 ④1,n-i
⑤s[j]<s[j-1] ⑥s[j]>s[j-1],则(1)(2)(3)处代码依次为( )
import random
def find(x, y):
m = (x+y+1)//2
if a[m] == key:
return m
if a[m] > key:
y = m-1
else:
x = m + 1
return find(x, y)
a = [2, 4, 6, 8, 10, 12, 14, 16]
key=random.choice(a) #从序列的元素中随机挑选一个元素
i = 0;j = len(a) - 1
xb = find(i, j)
print(xb, key)
上述程序执行完后,函数find被调用的最多次数是( )
def sym(d1, d2):
s1 = d1.split(",") # 以“,” 将字符串分割成列表
s2 = d2.split(",")
if len(s1) != len(s2):
return False
stk = []
i=0
j=0
while i < len(s1):
stk.append(s1[i])
i += 1
while stk != [] and stk[-1] == s2[j]:
stk.pop() #删除列表 stk 中的最后一个元素
j += 1
return stk == [] and i == j
L1 = "@,a,b,3,c,d"
L2 = input()
print(sym(L1, L2))
执行该程序段后,若输出结果为 True,则 L2 输入的值可能是( )

#导入相关模块,代码略
IP = "192.168.10.1" ; PORT = "5000" # Web 服务器的 IP 地址和端口
#设置 IoT 模块连接的 Web 服务器的 IP 地址和端口,代码略
while True:
temp, hum = dht11.read(pin0) #获取温度数据 temp,湿度数据 hum
light = pin1.read_analog() #获取光线强度数据 light
errno, resp = Obloq.get(" . " + str(temp) + "&hum=" + str(hum) +
"&light=" + str(light) ,60000)
# 其他代码略
若智能终端上传数据给Web服务器的URL为 //192.168.10.1:5000 /trans?
temp=30&hum=300&light=40,则程序划线处的代码应为。
if t1 < temp < t2:
flag = 1
B . flag = 1if not (temp < t1 and temp > t2):
flag = 0
C . flag = 1if temp <= t1:
flag = 0
if temp >= t2:
flag = 0
D . if not (temp <= t1 or temp >= t2):flag = 1
else:
flag = 0

def avg(filename):
df=pd.read_csv(filename)
df1=df[df.columns[2:]] # 取类型及其后的所有列
g=df1.groupby( ① ,as_index=False).mean()
return ②
划线②处应填入的代码为(单选,填字母)。
A.df[df.类型=='AQI'] B.df1.AQI C.g.AQI D.g[g.类型=='AQI']
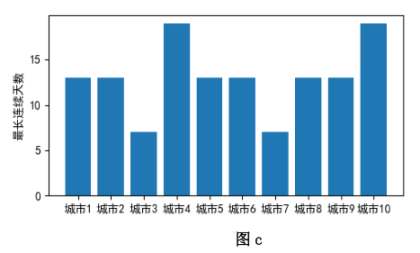
import pandas as pd
import matplotlib.pyplot as plt
n=10 #城市个数
count=[0]*n
daymax=[0]*n
for i in range(1,31):
day=str(i)
if len(day)<2:
day='0'+str(i)
daydata='202204'+day+'.csv'
dayaqi=avg(daydata)
city=dayaqi.columns[1:n+1]
for j in range(n):
t=city[j]
if dayaqi.at[0,t] <= 100:
else:
if count[j]>daymax[j]:
daymax[j]=count[j]
count[j]=0
for k in range(n):
if count[k]>daymax[k]:
print(daymax)
plt.figure(figsize=(12,4))
x=
y=daymax
plt.bar(x,y)
plt.show()
检查结果分为如下三种情况(以完成的任务数m=5为例说明):
①安排合理:完成的任务数大于等于m,且执行过程中无重复任务。例如:计划1完成任务的顺序为:任务0→任务6→任务4→任务1→任务5→结束(-1),共安排了5个任务。
②任务不足:完成的任务数小于m。例如:计划2完成任务的顺序为:任务6→任务2→任务0→任务1→结束(-1),只安排了4个任务,出错任务为任务1。
③任务重复:任务安装中存在重复任务。例如:计划3完成任务的顺序为:任务7→任务3→任务5→任务1→任务0→任务3→结束,其中任务3重复,出错任务为任务 0。
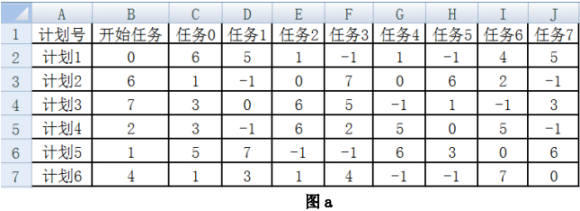
import pandas as pd
m = int(input('请输入需完成的最少任务数:'))
df = pd.read_excel('task.xlsx')
name = list(df.columns[2:]) #取任务名称
plan = list(df.计划号) #取计划号
task = list(df.values)
#task 中的保存 df 中的数据,不含标题。格式如图b所示

for i in range(len(task)):
head = task[i][1]
stat,k = check_up(link,head)
if stat == 2:
print(plan[i],':安排合理,共完成',k,'项任务')
elif :
print(plan[i],':任务重复,出错任务为',name[k])
else:
print(plan[i],':任务不足,出错任务为',name[k])
def check_up(link,head):
cnt=1
p=link[head]
pre=p
while p!= -1 and p not in finished:
finished.append(p)
pre = p
cnt+=1
if p==-1:
if cnt<m:
return 1,pre
else:
return 2,cnt
elif p in finished:
return 0,pre


